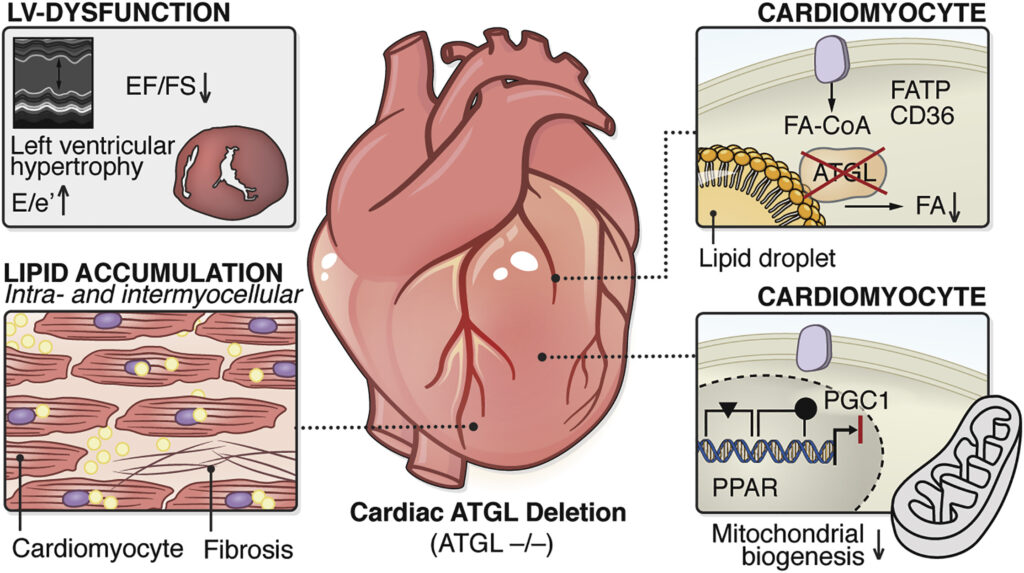
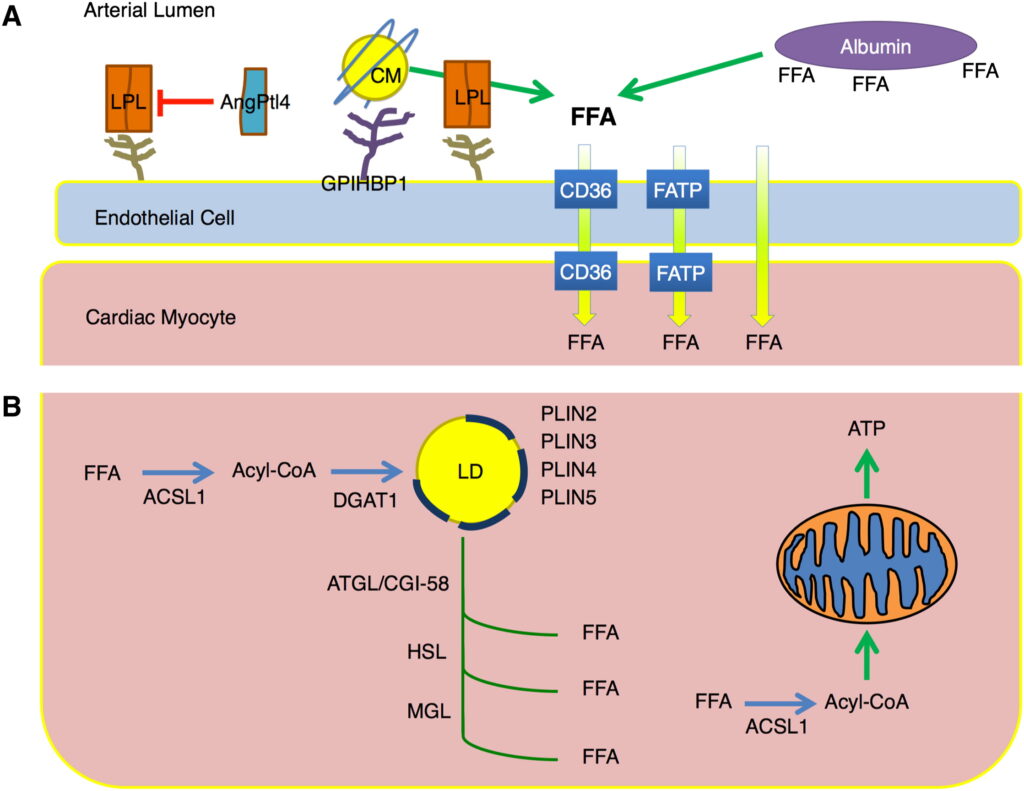
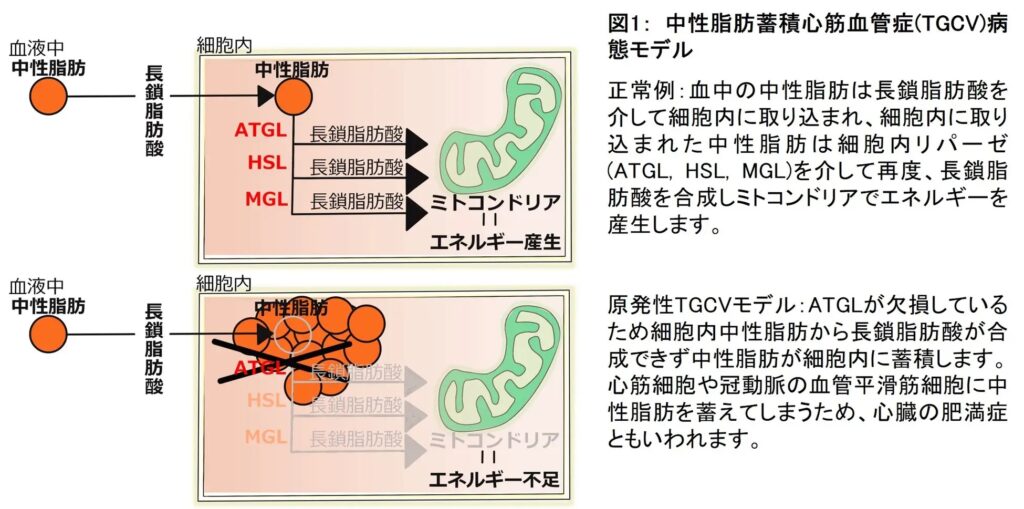
心臓核医学の領域では脂肪酸代謝を調べるときに123I-BMIPPをトレーサーに使い、その局在を画像化します。この画像検査法は、123I-BMIPPシンチグラフィーあるいは心筋脂肪酸代謝シンチグラフィーなどと呼ばれます。心筋で脂肪酸代謝が行われているのであれば、放射性同位体でラベルした脂肪酸である123I-BMIPPは心筋に取り込まれて、心筋への集積が観察されます。もし虚血(酸素が十分に存在していない状態)のために、
BMIPPとは
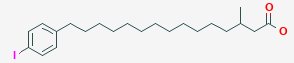
BMIPPは、β-methyl-p-iodophenyl-pentadecanoic acidの略です。この化合物の構造式は、下のようになっていて、右端にカルボキシル基-COOHがありますが、その右隣の位置にある炭素ががアルファ炭素、さらにその左隣りがベータ炭素と順に呼ばれますので、ベータ炭素にメチル基CH3-がついていることがわかります。左端を見ると、パラ(p)の位置にヨウ素がついたフェニル基があります。ペンタ(penta)は5を意味し、デカ(daca)は10の意味ですから、ペンタデカ(pentadeca)は15の意味で、炭素が15個の飽和脂肪酸であるペンタデカン酸(pentadecanoic acid )CH3(CH2)13COOHが骨格部分になっています。BMIPPは、ベータメチルパラヨードフェニルペンタデカン酸 というわけです。別称で、iodine-123-15(- p-iodophenyl)-3(- R, S)
-methylpentadecanoic acidとも呼ばれます。
- 2つの置換基の位置関係による命名(オルト-、メタ-、パラ-)
- カルディオダイン注
- http://jsnm.org/wp_jsnm/wp-content/themes/theme_jsnm/doc/shinzoukakuigakukensa_gl.pdf
ペンタデカン酸は炭素数が15ですが、炭素数16のヘキサデカン酸は、パルミチン酸(palmitic acid)としても知られていて、化学式CH3(CH2)14COOHで、ペンタデカン酸と炭素一個の長さの違いを除くと同じような構造の飽和脂肪酸です。パーム油(palm oil)の主要な構成成分なのでpalmitic acidの名があります。心臓核医学検査ガイドライン(2010年改訂版)を読むと、
123I-BMIPP[iodine-123-15(-p-iodophenyl)-3(-R,S)-methylpentadecanoicacid]は,パルミチン酸のβ位にメチル基を導入した側鎖型長鎖脂肪酸である532).
532. Knapp FF, Jr., Ambrose KR, Goodman MM. New radioiodinated methyl-branched fatty acids for cardiac studies. Eur J Nucl Med 1986; 12 Suppl: S39-44
と書いてありました。BMIPPの主鎖の炭素数は15であって16ではないので、この記述は違うような気がします。しかし引用されている文献は有料で中身が見られないので、どういう説明がされているのかはわかりません。余談になりますが、炭素の放射性同位体でラベルしたパルミチン酸もトレーサーとしての使用例もあります。こちらはベータ酸化されるため、ダイナミックな変化になります。
- 11Cパルミチン酸PETと123I-BMIPPスペクトの比較検討 日本放射線技術学会雑誌 1995 年
- 心筋症における[11] C-パルミチン酸PET : 肥大型心筋症での検討 1993-07-10
BMIPPの特徴
BMIPPは長い鎖(主鎖)から枝分かれ(側鎖)が出ています。ベータ炭素にメチル基がついているので、側鎖というのはこのメチル基のことです。ベータ炭素は、ベータ酸化の標的ですがそこにメチル基がついているため、BMIPPはベータ酸化されにくいという特徴があります。代謝されてなくなってしまわないので、トレーサーとして使いやすいというわけですね。
123I-BMIPPは生体内にある脂肪酸と同様の体内動態を示し、細胞内へ取り込まれた後、脂質プールおよびミトコンドリア内に移行します。側鎖としてβ位にメチル基があるためβ酸化を受けにくく、心筋内に長く留まります。(各医学検査のご案内 日本メジフィジックス)
- 則鎖(コトバンク)
- 心臓核医学検査ガイドライン(2010年改訂版)
ヨードに放射性同位体123Iを用いて、トレーサーとして用います。123I-BMIPPシンチグラフィーと呼ばれる画像検査法ですが、123I-BMIPPシンチとはどんな原理で何を測定することができるのでしょうか。
心筋脂肪酸代謝シンチグラフィーの原理
心筋のエネルギー源は主に糖分と脂肪酸です。通常は脂肪酸を優先して利用していますが、同時に酸素も消費します。心筋に障害が出始めると、そのエネルギー源を酸素を同時に消費する脂肪酸から酸素の消費を抑えることのできる糖分に変化させていきます。安静心筋シンチでは、123I-BMIPPという心筋の脂肪酸代謝を反映する検査薬と201Tlという心筋への血流を反映する検査薬を同時に用いて、心筋の障害の程度を確認します。123I-BMIPPが心筋に十分集まらず201Tlが心筋に集まった場合、その領域では心筋の障害がはじまっていて、エネルギー代謝を糖分に変化させている可能性があります。(安静心筋シンチ(201Tl, 123I-BMIPP) 心筋シンチ 国立国際医療センター病院)
心筋のエネルギー源は主に遊離脂肪酸とブドウ糖であり,空腹時健常心筋ではその約60%以上を脂肪酸のβ酸化に依存する. 一方虚血時には脂肪酸代謝は低下し, 解糖系が主なエネルギー源となる. 虚血が進むと中でも嫌気性解糖系が主となり,さらにその状態が進行すると,もはや代謝のない心筋壊死に至る.したがってPETを用いて心筋局所のエネルギー基質の利用率を計測することにより, 心筋虚血の程度を詳細に検討することが可能である(PETによる心筋代謝の解 析 心蔵VoL28 SUPPL1 (1996))
心筋細胞は好気的条件下ではATP産生基質として約60%をミトコンドリアにおける脂肪酸β酸化に依存している.この,好気的代謝は多くの酸素を必要とするため血流障害の影響を受けやすい.放射性側鎖脂肪酸製剤を用いて行われる心筋脂肪酸代謝イメージングでは,心筋ミトコンドリア内の脂肪酸β酸化の障害により心筋集積が低下する.(日本小児循環器学会雑誌 第30巻 第4号 https://www.jstage.jst.go.jp/article/jspccs/30/4/30_392/_pdf)
血流が低下した心筋虚血では脂肪酸に代わってブドウ糖などが利用されるようになります。脂肪酸代謝SPECTではしばしば血流の低下よりも高度な異常が見られ血流と代謝のバランスが変化していることを知ることができます。(金沢循環器病院https://www.kanazawa-heart.or.jp/disease/kensa_13.html)
脂肪酸代謝の放射性医薬品である123 I BMIPPは,日本で欧米に先駆けて臨床応用が実現した薬剤であり,日本でも多彩な研究が行われてきた.心筋におけるATP産生 の主要な経路は脂肪酸によるものであり,123 I BMIPPは 虚血に感度の高い薬剤として利用されている.(第46回 河口湖心臓討論会 https://www.jstage.jst.go.jp/article/shinzo/45/3/45_364/_pdf/-char/ja)
BIMPPの動態
静注直後より心筋へ速やかに取り込まれる。β酸化をほとんど受けないために心筋に安定して留まり,高画質のSPECT像が得られる。一部はα酸化を経てβ酸化を受けるが,犬では冠動脈投与のわずか6.6%が30分で代謝されるに過ぎない。人でも3時間後までの心筋からのクリアランスは10%程度である。したがって投与20-30分後にSPECTを施行することが一般的であり, (SPECTによる心筋代謝の評価 RADIOISOTOPES 46, 511 (1997))
心筋脂肪酸代謝シンチグラフィーで何がわかるのか
主にトリグリセライドプール(TGpool)に貯留する。心筋細胞は高度あるいは長期の虚血に陥ると脂肪酸の心筋への貯留が減少し,その取り込み異常は血流異常より早期に且つ高度に起こる。強い虚血のエピソードが起こると,最低でも1-2週間は脂肪酸取り込み障害が残るため,BMIPPにより過去の虚血エピソードを観ることができる(memoryimaging)。BMIPPの取り込み低下は虚血関連では心筋梗塞,冠攣縮,労作性狭心症で認められるが集積異常は虚血重症度と相関すると考えて良い。(123I-BMIPP心筋シンチの臨床活用とその読影法 臨床核医学)
心筋梗塞を起こしている部分(←)はすでに心筋が死んでしまっている為、負荷時、安静時ともに「放射性医薬品」は取り込まれません。(【心臓の検査】心筋シンチグラフィをお受けになる患者さんへ 日本メジフィジックス)